
Recursive, Nuts & Bolts Part 2 - Crawling the World Wide Web (2 of 3)
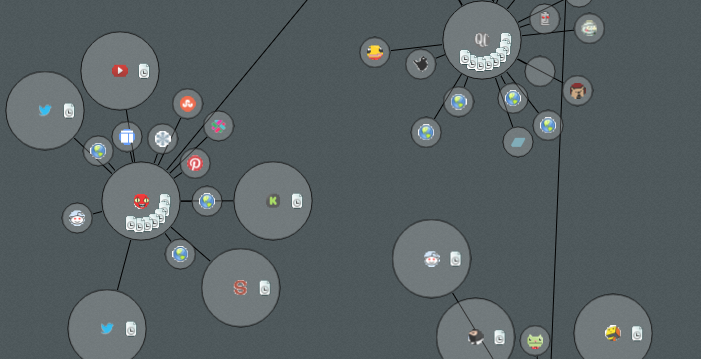
This is part two of my three part series on the internals of Recursive, an extension for Google Chrome. In the first post I laid the groundwork for the contents of this and the next post. In this post i'm going to talk a little about what Recursive does internally once given a URL.
Chrome Crawler
Recursive is actually based on an extension called Chrome Crawler I wrote about a year ago, but I had to change the name of due to Google's branding policy for Chrome Extensions. So although Recursive was rewritten from the ground up, a lot of the ideas discussed below stem from that project.
Cross-Origin XMLHttpRequest
Much in the same way that search engine crawlers work, Recursive, downloads a url, scans it for links then recursively follows them.
Normally this sort of behaviour isn’t permitted to Javascript (or Flash for that matter) when running within a web page due to the Same Origin Policy without specific permission from the server you are calling. Chrome extensions however don't have this restriction and thus (with permission given in the extension manifest) the extension is able to download content from any server.
This special behaviour is called the Cross-Origin XMLHttpRequest and is what allows Recursive to work its magic.
Code Structure
As briefly mentioned in the previous post the Crawling logic is separated from the Rendering logic. This differs from how Chrome Crawler was implemented where he rendering and crawling logic were mushed together. This separation took a little more thought and planning the result however is that the crawling logic makes much more sense and doesn't contain anything that doesn't purely pertain to the logic and data involved with crawling.
The crawling code is split up into three main files the Graph, the Crawler and the Parser.
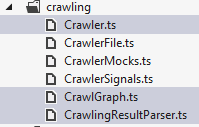
The Graph is the central class that drives the crawling process. Only one of these exists for the application. It provides a number of functions for starting, stopping and pausing the crawling process. It also has a number of events (exposed through signals) that it uses to let listeners (the renderer) know when a particular event occurs.
The Crawler represents a single crawl instance. Its responsibility is to follow a single URL then report when it progresses, returns or errors. The Parser takes the returned HTML from the Crawler and scans it looking for links and files. It then returns the results which are then stored in the Crawler instance.
Parsing Problems
One issue I encountered while developing Recursive (and Chrome Crawler) was the performance and security issues involved with parsing the HTML returned from the crawl. The way I originally handled this was to pass the entire HTML to JQuery then ask it for all ‘src’ and ‘href’ attributes:
function getAllLinksOnPage(page)
{
var links = new Array();
$(page).find('[src]').each(function(){ links.push($(this).attr('src')); });
$(page).find('[href]').each(function(){ links.push($(this).attr('href')) });
return links;
}
The problem with this is that behind the scenes jQuery is constructing a DOM which it uses for querying. Normally this is what you want, but in this instance its a problem because its rather slow process, also the browser executes the script tags and other elements when it generates the DOM. The result of which is the crawling is really slow and there were many security errors generated while crawling.
The solution was to use regex to parse the HTML and look for the attributes manually like so:
var links = new string[];
// Grab all HREF links
var results = c.pageHTML.match(/hrefs*=s*"([^"]*)/g);
if (results) results.forEach(s=>links.push(s.split(""")[1]));
// And all SRC links
results = c.pageHTML.match(/srcs*=s*"([^"]*)/g);
if (results) results.forEach(s=>links.push(s.split(""")[1]));
I was worried that the sheer amount of html text that must be parsed by the regex would result in things being really slow however it seems to hold up quite well, and is definitely not the bottle neck in the app.
Custom File Filter
One addition to the result parsing that was added in v.1.1 was the ability to define a custom file filter:
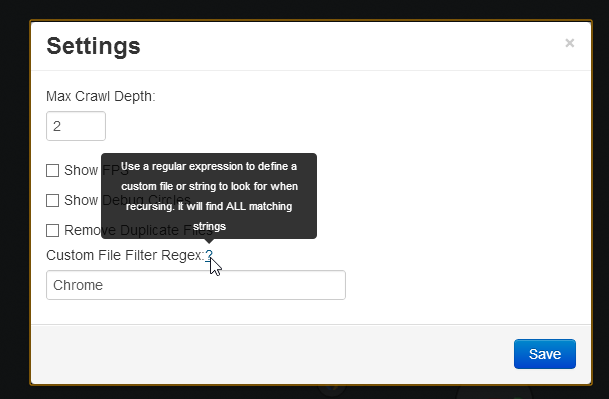
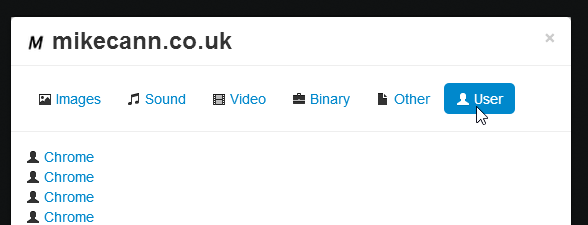
Enabling this adds a third regex call into the results parser. Any matches are added to the Crawler’s files as a special kind of file. When the user opens the files dialog all the matches are shown under a special category:
Improvements
Although the regex doesn't take very long to execute when parsing the HTML I had the thought that Javascript workers could be used to take advantage of the multiple cores that are present in most CPUs these days. Perhaps if I decide to perform some more complex sort of parsing i'll revisit this idea.
Finally
Thats about it for part two of my three part discussion on some of the internals of Recursive. Head over to the third part to find out more about the layout and rendering of the returned data.